
A Brief Apache Arrow Tutorial by Open Data Architecture Expert
-
 By
Alex Merced
, Developer Advocate at Dremio
By
Alex Merced
, Developer Advocate at Dremio - Best Practices,
![]()
Solutions Review’s Expert Insights Series is a collection of contributed articles written by industry experts in enterprise software categories. In this feature, Dremio Developer Advocate Alex Merced offers a brief Apache Arrow tutorial with advice for getting started.
 The open-source Apache Arrow project has been transforming the data landscape for the better since its release in 2016, helping to solve the challenges of moving and analyzing large data sets. Fundamentally making data processing and transport faster and cheaper, Apache Arrow provides a powerful, flexible platform for working with big data across different systems and programming languages.
The open-source Apache Arrow project has been transforming the data landscape for the better since its release in 2016, helping to solve the challenges of moving and analyzing large data sets. Fundamentally making data processing and transport faster and cheaper, Apache Arrow provides a powerful, flexible platform for working with big data across different systems and programming languages.
Several of its key innovations enable analytical tooling to be more performant. These include:
- In-memory columnar format: Apache Arrow offers this standard format for how to represent data for analytics in memory. Having a standard format reduces the need to serialize and deserialize between proprietary formats. Arrow supports random access streaming and batch scan workloads.
- Language Libraries: Arrow’s libraries for working with its standard format span more than 12 programming languages, making the benefits available in most languages that developers are using to build tooling. Languages include C, C++, C#, Java, Go, Rust, Python, Javascript, R, Julia, MATLAB, and Ruby.
- Apache Arrow Gandiva: This part of the Arrow project allows for the creation of SQL User Defined Functions (UDFs) for working with Arrow-based data, which can be pre-compiled to native code for improved performance.
- Apache Arrow Flight: Flight is a protocol for transporting Arrow Data over the wire, meant to substitute traditionally row-based options such as JDBC/ODBC, which would reduce performance due to serialization and deserialization. With Arrow Flight, we can extend the performance benefits, not just in faster processing, but in faster transport. This video shows the performance difference between Apache Arrow and ODBC in Python. The transport protocol is implemented as a gRPC API, which means a client implemented in any language can speak to any source implementing the spec. One client is all you need.
- Apache Arrow ODBC/JDBC Drivers: To make using Flight easier, Arrow now has ODBC/JDBC drivers that allow developers to leverage the patterns they are used to, but with the speed benefits of Arrow. The Arrow driver can help connect to any Arrow supporting source, ending the days of having to download and configure many drivers.

Apache Arrow Tutorial
How to Begin Working with Arrow
If you are doing analytics, you don’t need to adopt Arrow directly but ensure the platforms, tools, and libraries you are working with take advantage of Arrow. Ask yourself:
- Does the query engine that I use to process data use Apache Arrow, and is there an Apache Arrow Flight endpoint for me to pull data from performantly?
- Do the libraries I use for analytics support work with Apache Arrow Buffers, Tables, RecordBatchReaders and other objects?
Some of the options that answer these questions and offer support for Arrow include: Dremio, Datafusion, Acero, Apache Parquet, Bodo, Clickhouse, Apache Spark, Cylon, Graphique, Dask, InfluxDB, Pandas, Polars, Ray and DuckDB.
To get the full benefit of Apache Arrow, you essentially want three things: (1) a query engine that uses Arrow and has an Arrow Flight endpoint; (2) use of Arrow Flight or the Arrow Flight ODBC/JDBC drivers to connect via Arrow Flight; and (3) the ability to pull down the data you need, then continue running analytics with libraries that support Apache Arrow. If these things are true, the queries, transport and local ad hoc analysis will see huge improvement, which can also translate into cost savings through less compute costs.
Tools Easily Work Together
Many tools support Arrow and to demonstrate how easily they can work together, below is a Python code example of pulling down data from an Arrow Flight endpoint from Dremio, then taking the Arrow data and passing it to DuckDB for local management. Users can enjoy this kind of easy experience with an array of tools that support Arrow and Flight.
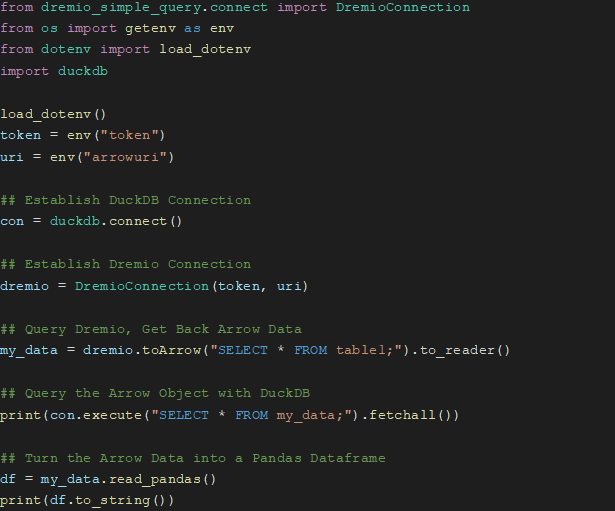
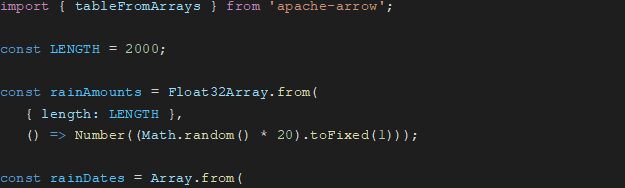
Here’s another example. This one uses Arrow in Javascript from the documentation. Here, arrays are created to represent different columns of a table and then converted into an Arrow table.

A Ubiquitous Piece of the Fabric
Efficient data transfer, fast processing, cross-platform compatibility, memory optimization and standardization are among the key benefits Arrow delivers. Because data is stored in a columnar format, it can be accessed and processed more readily. Columnar data storage allows for efficient vectorized processing, which can significantly improve processing times, especially when working with large datasets. For memory optimization, Arrow uses a “zero copy” approach designed to minimize memory usage, which allows data to be passed between systems without copying it into new memory buffers.
By providing a standard in-memory format that allows different software and tools to exchange data at little to no performance cost and by providing libraries for working with that format in most languages, Apache Arrow greatly reduces the costs of transporting data across the wire.
Arrow’s standardization simplifies data integration and makes it easier to build tools that work with data from different sources. Arrow is on a trajectory to become a ubiquitous piece of the fabric for all our favorite data tools.

Alex Merced
Developer Advocate
Alex Merced is a Developer Advocate for Dremio, focusing on educating the industry about using open data architecture with open source technologies such as Apache Iceberg, Apache Arrow, Project Nessie and more. Alex Merced is the host of several data podcasts such as Gnarly Data Waves, DataNation and co-host of “Select * from data.lake”. Alex Merced has worked as a developer for companies Crossfield Digital, Gened Systems, CampusGuard and has trained engineers as an instructor at General Assembly.
- From Prompt Design to Data Engineering: Why Architecture Matters for Agentic AI - December 12, 2025
















