

This is part of Solutions Review’s Premium Content Series, a collection of contributed columns written by industry experts in maturing software categories. In this submission, Monte Carlo Head of Customer Success Will Robins shares some bad data examples, with insights on why bad data is becoming a bigger pain point for companies.
 We have all experienced the pain of bad data. It could be an urgent call from the C-suite about missing data or duplicate tables in your data environment. When data is wrong or outdated it is referred to as data downtime, and as data becomes more valuable, this downtime becomes more problematic. In this post, we will cover 8 reasons why bad data is becoming more problematic.
We have all experienced the pain of bad data. It could be an urgent call from the C-suite about missing data or duplicate tables in your data environment. When data is wrong or outdated it is referred to as data downtime, and as data becomes more valuable, this downtime becomes more problematic. In this post, we will cover 8 reasons why bad data is becoming more problematic.

Data is Floating Downstream
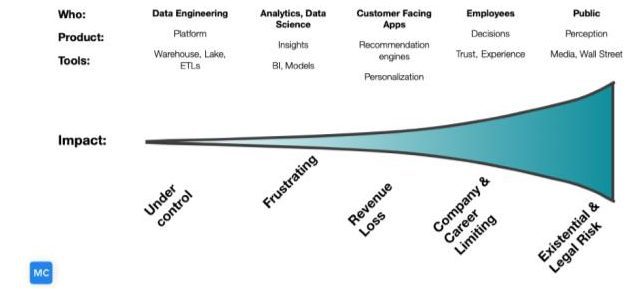
When bad data is identified and remediated by a data engineer there are no problems. However, if it’s caught by the general public out in the wild, there could be significant consequences.
Each stage can also filter bad data before it moves downstream. However, there are currently multiple drivers accelerating the pace of data downstream including data democratization, reverse ETL, and much more.
Data Platforms are Getting Complicated
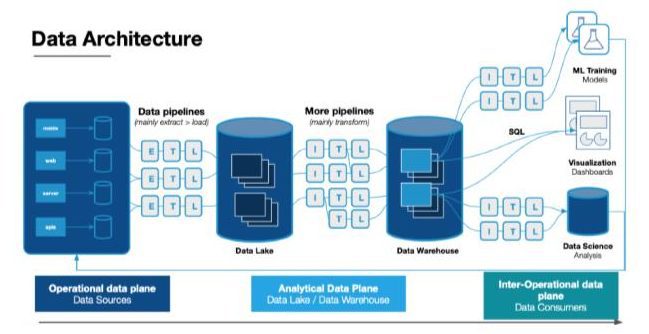
It’s more problematic the further downstream bad data travels because it is harder to mitigate. You would much rather have a data engineer fix a broken pipeline than for a member of the data team to have to fix a machine learning model that has drifted on poor data quality.
It’s not just the mitigation of these issues that is problematic. As organizations depend on complicated data platforms to make decisions, the opportunity costs of bad data rise as well.
One example would be a finance organization with ML models to purchase bonds when they meet certain thresholds. Errors in the schema could crash this model for weeks and prevent this group from executing.
With increasingly complicated data platforms there are more moving parts, which can create more opportunities for issues to arise.
More Adoption of Data
Odds are data adoption has increased at your organization. Companies have recognized that in order to be data-driven, they need to drive data adoption.
According to a Google Cloud and Harvard Business Review report, 97 percent of surveyed industry leaders believe organization-wide access to data and analytics is critical to the success of their business.
This is not a bad thing, but as data adoption increases at your organization that results in more idle professionals when your data is bad.
Increasing Data Expectations
Your organization has big expectations for its data quality. They think data should just be like the SaaS products they have been using that never go down. Unfortunately, not too many data teams can say their data platforms are at a SaaS reliability level.
Today many teams are evaluated quantitatively rather than quantitatively, which means making life difficult for your data consumers can have consequences. Keeping data quality high and routinely evangelizing your quality metrics can help.
It’s Tough to Hire a Data Engineer
Data teams are constantly telling me how hard it is to hire data engineers.
Data engineering was one of the fastest growing jobs in the Dice 2020 Tech Job Report with an average salary of more than $115,000 according to the 2022 Report.
So, if data engineering time is scarce, it’s a better idea to automate your data quality and monitoring rather than having them spend their time (some studies show 30 to 50 percent!) to fix broken pipelines.
Diffusion of Data Quality Responsibilities
Data mesh, which federates data ownership among domain data owners who are held accountable for providing their data as products, is a big trend in data currently.
This gets the data team closer to the business, but it can also distribute responsibility. To prevent issues from arising, teams need to have constant, proactive communication. Otherwise, the time to resolve data issues across domains can become problematic.
Cookie Deprecation
By now, most data professionals are aware that the cookie is crumbling thanks to GDPR. This means companies that outsourced their targeting to third parties are going to need to rely on first-party data again.
And that first-party data will need to be reliable.
It’s a Competitive Market for Data Products
It’s amazing to see all the innovative data products being produced by data teams. In some industries, especially in media and advertising, it is becoming super competitive.
Consumers expect more data, more interaction, and less latency. It’s crazy to see how these data products are moving from hourly batching to 15 minutes, to every 5 minutes, and now starting to stream.
There is no room for bad data in these products–not if you want to be competitive.
Prevention is the Best Fix
Most organizations underestimate the extent of their data quality issue and therefore underinvest time and resources into solving the challenge.
A proactive, multi-pronged approach across teams, organizational structure, and tooling can help lower the increasing cost of data downtime.

Will Robins
Will Robins is the head of customer success at Monte Carlo. Monte Carlo, the data reliability company, is creator of the industry’s first end-to-end data observability platform. Monte Carlo works with such data-driven companies as Fox, Affirm, Vimeo, ThredUp, PagerDuty, and other leading enterprises to help them achieve trust in data.
















