

This is part of Solutions Review’s Premium Content Series, a collection of contributed columns written by industry experts in maturing software categories. In this submission, Normalyze Co-Founder and CTO Ravi Ithal offers the essential factors to consider when doing cloud data security as a non-engineer.
 Most business leaders are not technical experts in cloud, agile, AI, cybersecurity, networking, and everything else that goes with being a modern enterprise. But with a modern thrust, they all know that data are the organization’s most valuable asset. Being risk averse, it’s why they increasingly question security professionals: “Is our data safe?” “How do we know it’s safe?” Or “If there are vulnerabilities, when will these be fixed?”
Most business leaders are not technical experts in cloud, agile, AI, cybersecurity, networking, and everything else that goes with being a modern enterprise. But with a modern thrust, they all know that data are the organization’s most valuable asset. Being risk averse, it’s why they increasingly question security professionals: “Is our data safe?” “How do we know it’s safe?” Or “If there are vulnerabilities, when will these be fixed?”
If your responses are, “Don’t know, not sure how to tell, and have no idea,” then this article is for you.

Why Securing Cloud Data Is Harder
In the security world, we often say you can’t protect something if you don’t know it’s there. This maxim is relevant to securing cloud data. If your organization relies on a cloud architecture – especially multiple clouds and other service providers – it is harder to know where your data is 100 percent of the time.
Protecting data was easier in the past when an enterprise used just a handful of cloud services. Most of the IT infrastructure was on premises, and database servers were under direct physical and logical control of the organization’s staff. Consequently, security operations knew exactly where to place controls to protect the data. Everything was under control!
In a modern world, organizations are shifting or even focusing workloads and data off premises and into the cloud. Structured and unstructured enterprise data are growing because AI/ML systems have a deep thirst for data. The cloud workloads typically involve data copied from production and transferred to another cloud. Data proliferation is particularly challenging for organizations using infrastructure-as-a-service and infrastructure-as-code. As a result, data sprawl complicates processes for security teams to discover, classify, and protect the data.
To be clear: offloading architecture operations to service providers does not let an enterprise off the hook for security. The shared responsibility model defines a line between what your security team is responsible for versus the providers. Understanding a security team’s role will clarify what they must do for reducing the risks of cloud-based vulnerabilities to protect the data.
3 Engineering Factors for Securing Cloud Data: Volume, Variety, Velocity
Security operations teams should approach cloud data protection by getting familiar with basic themes addressed by data engineering. Conveniently, these issues all seem to start with the letter “V” and there are many opinions on whether there are 3 V’s, 4 V’s, 5’Vs and more! Here we’ll focus on the original Big Three: Volume, Variety, and Velocity.
Volume – The amount of data
Digital transformation is causing the tally of all data created, copied, and used globally to soar beyond comprehension. The total volume projected for 2022 is 97 zettabytes, according to Statista. By comparison, 97 zettabytes is equal to 97 trillion gigabytes or 97 billion terabytes.
To understand this volume of data, consider a scenario with streaming video. A 120-minute movie streamed at 4K resolution consumes about 84MB/minute, or 10GB per movie. Movie buffs claim there have been about 500,000 total feature length movies made and streaming all of them (assuming they were 4K quality) would consume about 5 million GB. Total viewing time to watch all 500,000 movies would be 115.74 years. Doing the math, you’d need to stream all 500,000 videos 1,940 times to consume 97 zettabytes. Get your popcorn ready!
Based on the global total volume of data created between 2010 and 2020, Figure 1 shows growth projections through 2025.
Volume of data/information created, captured, copied, and consumed worldwide from 2010 to 2025 (Statistica)
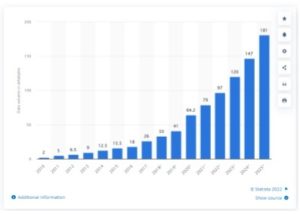
A modern enterprise creates much less data than these global figures, but the growth slope would be similar and poses significant challenges for cloud data security. Everything your security team does for locating, classifying and protecting the data must be able to scale with a dynamically rising volume.
Variety – Types of data
As we consider data variety or types, data management engineers focus on how data is stored and manipulated. The classic data store is a structured database containing numbers and/or text. A relational database organizes these data as a collection of related tables. Another data store is unstructured, such as images, video or audio. Data may also be semistructured, which does not conform to the tabular structure of structured data models but still includes tags or markers to assist with managing this content. We see these data types and a wide variety of various structured, unstructured and semi-structured datastores, file and block stores, data warehouses and more. Even within a variety you have an additional variety in vendors and dialects such as PostgreSQL, MySQL, DynamoDB, Elastic, S3, GCS, EBS, Snowflake etc. This variety is a developer’s dream but a CISO’s nightmare.
From a security perspective, variety pertains more to what the data represent – i.e., the many types of sensitive data that must be discovered and protected from attackers. Variety for security entails different classifications of sensitivity for compliance mandates that are defined by laws and business or industry regulations.
Variety also pertains to an organization’s policy on data that contains information about customers, partners, and employees; intellectual property; product development plans; marketing campaigns, internal financial plans – anything proprietary to the business.
The security team’s priority is to know exactly what each kind of data are and their protection priority. Within the multiple and sometimes unpredictable places where data may be stored in the enterprise’s clouds, the team will need to immediately identify:
Personally Identifiable Information (PII) for federal privacy laws and regulations
- General Data Protection Regulation (GDPR) data
- Health Insurance Portability and Accountability Act (HIPAA) data
- Payment Card Industry Data Security Standard (PCI DSS) payment account data
- Data specified by other state or local laws and regulations
- Controlled unclassified information (CUI)
- Confidential business information (CBI) and other data specified by the organization’s security policy
Operationalizing a process to identify a wide variety of data types at scale will require substantial efforts without automation. Differences in protected data types are beyond the capability of one individual to manage, so if a manual approach is used, a team of experts will be required to assure detection and protection of each classification.
Locating each data type is also a big challenge due to unpredictable places where protected data might be copied … and forgotten somewhere in the cloud. Automation should play a major role in fulfilling requirements to quickly identify a variety of protected data types at scale.
Velocity – Speed of data creation
Velocity entails the rate at which new data is being created or acquired or distributed elsewhere. In the chart above, we see the “hockey stick” curve that indicates a dramatically accelerating velocity. For data engineering, velocity is normally associated with increased requirements for processing the new data. For security, it’s useful to think of velocity in terms of ramping a security team’s capability to keep up with finding sensitive data within the firehose of new data.
The velocity of data creation is soaring for several reasons. One is accelerated SaaS adoption; another is internet-of-things sensors generating enormous datastreams at scale. As mentioned, AI/ML systems have a deep thirst for data, especially with an acceleration of modeling for development and production of digital transformation.
Velocity is also rising with an explosion of new microservices with an ever-growing frequency of changes and constant iterations of code by DevOps. These workloads typically involve multiple copies of data produced, maintained and accessed as new microservices pop up to support new applications and features. This scenario can also trigger shadow data stores and abandoned databases.
Obviously, it is not possible to beat the challenge of velocity without using automation. For this reason, some organizations opt to act by creating their own tools, which can take months and burn significant budgets.
A few months ago, I met with a team at a global fintech provider. As we discussed these issues, one person said: “Where were you two years ago? It took us a team of 10 people and a $2 million budget to build a tool – just to handle our on-prem datastores!”
Building a velocity-hardened solution in house is an option but is not for the faint-of-heart!
Using Automation to Get Control of Cloud Data Security
The key lesson from this discussion is security teams need to employ some type of automation to deal with modern risks to cloud data security. There are other issues too, such as ensuring that access to cloud data is properly configured for all access to all places where protected data exists in the cloud. For each of these, your team will need to spot access misconfigurations, inflated access privileges, dormant users, vulnerable applications, and exposed resources with access to sensitive data.
Securing cloud data is a large, complex challenge that cannot be solved with manual processes alone. To get to automation, the team must use a tool or combination of tools. A security or engineering leader will need to decide: Shall we build this or buy a solution? Mid-level leaders will instinctively know that a homebrew solution will be far more difficult to manage at scale than a commercial cloud-based solution. Operations-level managers and engineers will be open to anything that solves their problem today.
For these reasons, if your organization needs to begin leveraging an automated approach, be aware there are solutions out there that can minimize manual work and improve automated workflows. They are called Data Security Posture Management solutions or DSPMs for short. DSPMs can quickly help reduce the attack surface, reduce the risk of data exposure and improve cloud security posture of protected or sensitive data.

Ravi Ithal
Ravi Ithal is the cofounder and CTO of Normalyze. He has extensive background in enterprise and cloud security. Before Normalyze, Ravi was the cofounder and chief architect of Netskope, a leading provider of cloud-native solutions to businesses for data protection and defense against threats in the cloud.

















