
Handling requests from Web Server (IIS) to Application Server (ASP.NET) can lead to performance and scalability issues. Often caused by misconfiguration — not scaling IIS and ASP.NET modules or custom code built without fully understanding what IIS & ASP.NET are executing behind the scenes — when handling requests. While this is not a new problem, it is a problem that software architects or lead developers often ignore. They ignore it until the slowdown of a service or application impacts real end users that are complaining.
It becomes even more important when building highly-distributed applications combining stacks and services. The following example illustrates the Dynatrace Service Flow for a distributed .NET & Java Application running in a hybrid cloud environment. Scalability issues between two tiers will have a cascading effect to all other tiers and your end users:
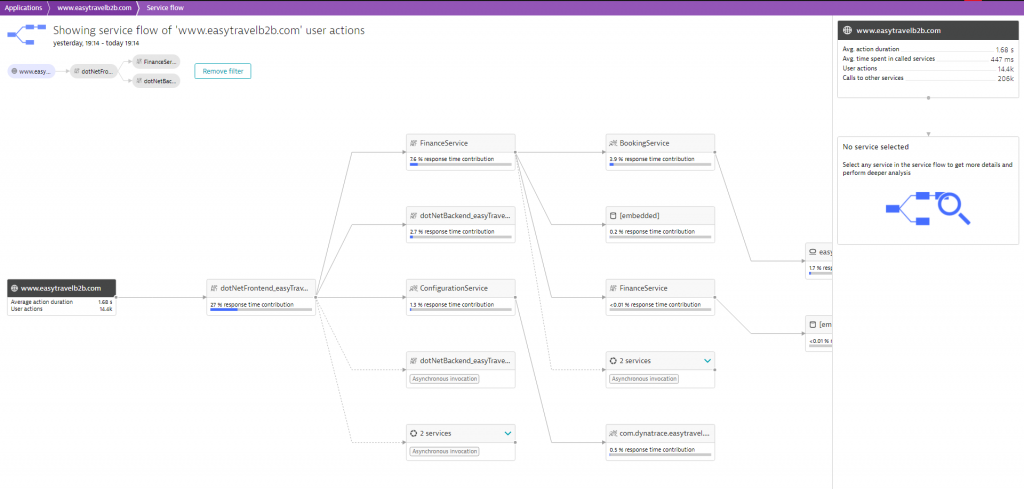
In the rest of this blog post, I walk you through the steps to detect a well-known ASP.NET Session State manager locking issue that results in scalability issues between IIS and ASP.NET. It was brought to my attention at a recent customer engagement. I hope this article inspires software developers and architects to find better solutions when building highly-scalable applications based on Microsoft’s technology stack!
Step #1: Becoming aware of scalability issues
I became aware of this problem when I worked with a customer who reported that they had a problem on one of their internal facing web applications. For the majority of the users of this internal application was working as expected, but for others performance was very poor and unacceptable.
Hitting the refresh button, restarting the browser, and reloading the application was becoming a habit for users who didn’t want to spend most of their day staring out the spinning wheel of wait aka “world wide wait annoyance”! That was when individual users started opening support tickets.
Step #2: Collecting evidence – 100% of the time!
Back when complaints about intermittent issues represented a big challenge for tech support, operations or architects. The advances in Application Performance Monitoring clearly made a huge positive impact on troubleshooting and finding root cause of large, small and intermittent problems. Instead of the classical blame game between network, DBAs and application owners APM solutions such as Dynatrace AppMon, as well as Dynatrace FullStack, provide clear evidence of where the root cause is located.
The primary advantage of Dynatrace and its PurePath technology is that it captures every single request, end-to-end, throughout the entire stack on which it is deployed on. Even when only a small percentage of users (or a single individual) experience a problem, it is still possible to find the relevant data and investigate. Most monitoring solutions only sample. Sampling means that they will never capture information about individual users, making it very difficult to find the real root cause of intermittent issues.
Many APM vendors that don’t have a 100% capture capability claim that you don’t need 100% of detailed data. I must say that our customers strongly disagree. In my previous job I worked on an e-commerce site where 1% of the users were reporting problems. You might not think that it is a big deal but when these users generate a large chunk of the revenue people start to take their complaints seriously.
In our IIS/ASP.NET scenario, it became rapidly apparent that a small number of requests were taking a long time. In extreme cases the response time could take minutes. 100% captured PurePath was the only reason we could find out what was wrong!
Step #3: Pinpoint problem area, then drill into PurePath
First, I do agree that Dynatrace AppMon collects a lot of data. Data is great but we understand that it can also be overwhelming. The proper approach to performance analysis is to start with a high-level view on key performance and quality metrics. Dynatrace provides many of these dashboards out-of-the-box. These dashboards are great to see “the big picture” but also allow us to drill further into technical details right from here:
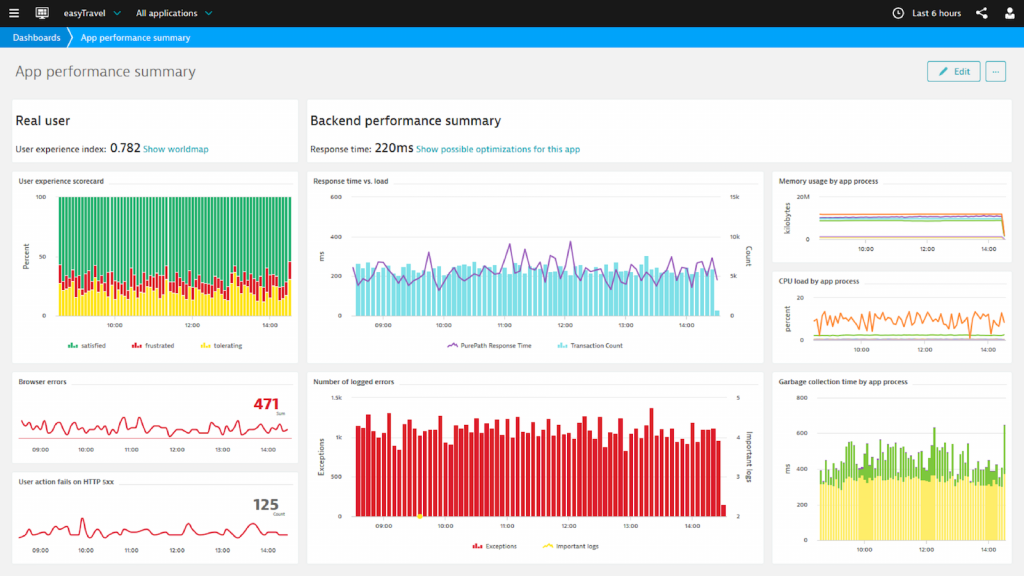
Besides the out-of-the-box dashboards we can also create custom dashboards for specific environments. From here, we quickly identify the problematic timeframe, a problematic endpoint or URL, or a problematic individual user. Once we have pinpointed that data set we drill into more details, looking at a complete end-to-end user session or even individual PurePaths.
Let’s start with the dashboard that I created for our application in question. The following screenshot perfectly highlights the problem that some of these users were reporting. Individual transactions that clearly take too long:
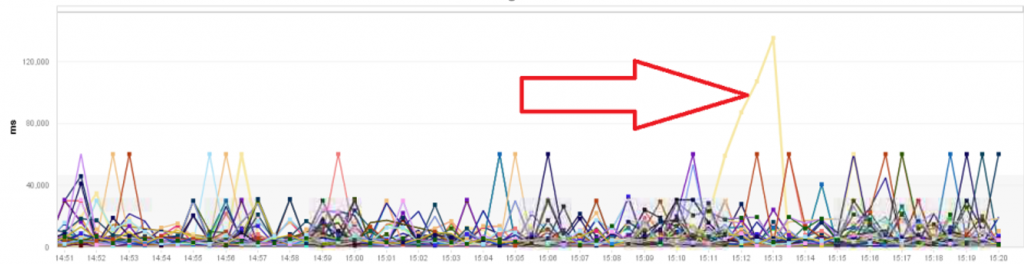
My personal approach is to either chart percentiles (to highlight 5 or 10% outliers) or simply chart maximum response time per application, endpoint or service. Dynatrace calculates these data points for every single request, which made it easy for me to find the time window of one of these intermittent problems.
From here, it is a simple drill down to the underlying PurePath that was responsible for this particular outlier:
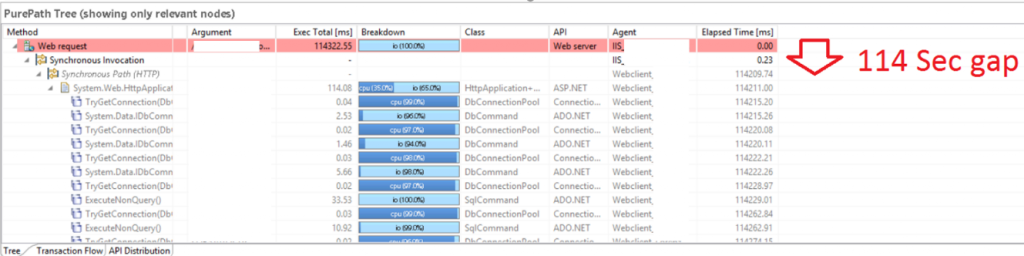
Looking at the PurePath I got a feeling what might be wrong here. Requests received by IIS were not forwarded immediately to the ASP.NET runtime. The Elapsed Time column in the PurePath tree shows us that it took 114s until the request ended up in the ASP.NET engine!
This type of behaviour has been reported by many customers with whom I have worked. Most common root cause is usually either a slow native IIS module (authentication, logging, encryption, URL rewrites) or threading issues (not enough available ASP.NET worker threads). My colleague Andreas Grabner has written several articles about similar issues such as problems that arise with bad Microservice Patterns.
Step #4: Investigating the technical root cause
In our case, we were not sure whether it was a native module, a misconfiguration, or an overloaded ASP.NET engine that ran out of worker threads, so we decided to continue our investigation.
By using the information provided by the Dynatrace UEM (User Experience Monitoring) Visit dashlet, I could see that the spikes reported on the chart did coincide with user actions followed by multiple rapid AJAX (XHR) calls.
The application used a rather outdated front-end JavaScript framework. That is why Dynatrace UEM couldn’t detect all browser-side AJAX calls out-of-the-box. Thanks to the 100% “always on” capturing, Dynatrace captures every server-side request, and is also aware of the initiating browser session. Even for older JavaScript frameworks this means we are not missing any important details. These types of AJAX/XHR calls are displayed as grey items on the visitors User Action list (see below). These requests are what we call “orphaned web requests”. Because of that feature we can understand which requests were executed by the browser in which sequence as we can see in the following screenshot.
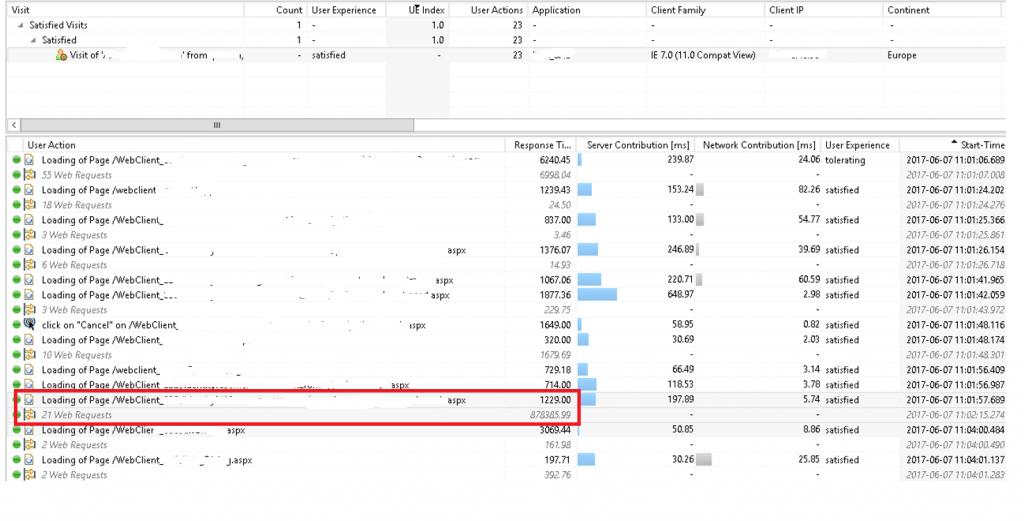
From the list of User Actions I drilled into the actual PurePaths that were captured. I could see that many were issued at the same time or extremely close to each other. By looking at the start and end time for each request, I could clearly see that none of them were processed in parallel! Each request seemed to be queued. It became more apparent when I sorted the PurePath’s by end time instead of start time:
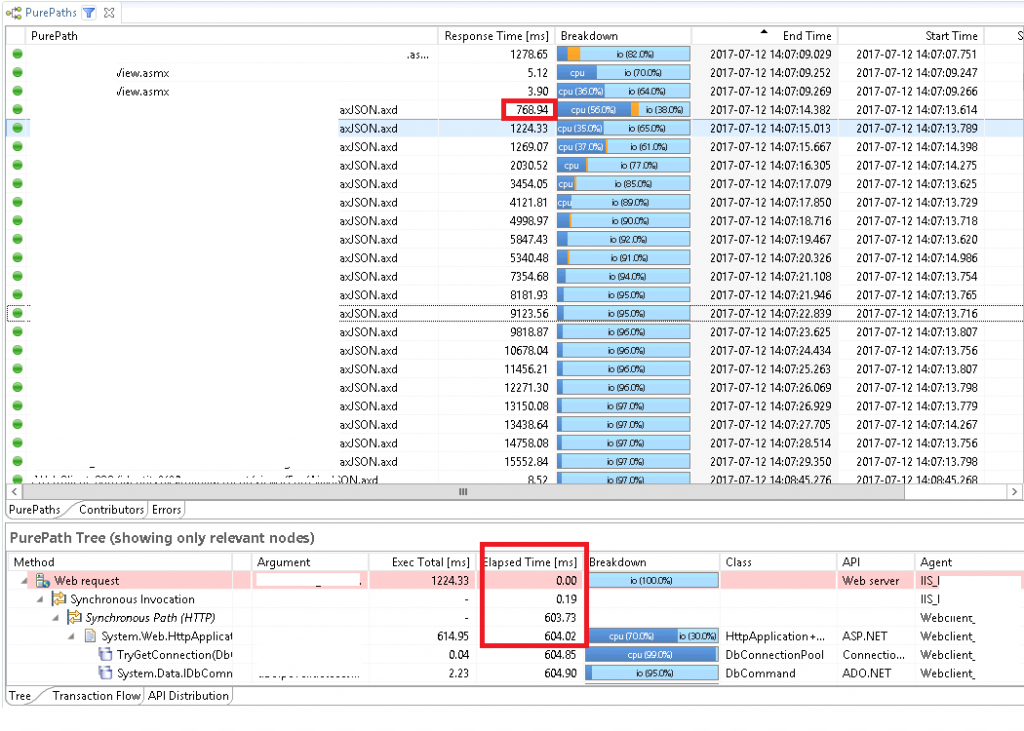
We can see that each request is taking longer and longer starting with the first one at 768ms all the way to 15552ms. The longer the response time, the bigger the gap between IIS and the asp.net part.
I have highlighted the second request to show that it is waiting for 603ms until the processing start, which is roughly the execution time of the previous request, with a 100ms delays as the second request was fired slightly later.
A search on the internet explained that the .NET framework tries to use the parallelism of Internet Explorer by firing multiple AJAX calls for the same user to multithread the requests and get better performance. This sounds great but I could see that something was not working correctly as the requests were not processed in parallel at all.
After more research online, I discovered that the session manager locks access to the session at the user level and, therefore, requests are processed sequentially.
I encourage you to read the official Microsoft article on ASP.NET Session State:
Learning for the next architectural decisions
The good news is that my customer is now aware of what was going on. The bad news is that it would require quite a few code changes to avoid using the session or making it read-only. I do hope that this write up will help for the next project you start, as making bigger architectural and implementation changes at a later stage become costlier.
If you want to see Dynatrace for yourself I encourage you to sign up for our free trials. The deep-dive application focused product I primarily showed you in this blog is available as our On-Premises Dynatrace AppMon Free Trial. More good news is that it stays free after the trial period ends, so that developers and architects can use it to validate their code changes and architectural decisions before pushing them through the continuous delivery pipeline.
If you are dealing with applications that are deployed in virtual, container or cloud environments, and you want to focus on full stack monitoring, I encourage you to give our Dynatrace FullStack SaaS trial a shot. You start collecting data in minutes! And, thanks to Dynatrace Artificial Intelligence, we automatically tell you if you really have a problem, and whether that’s related to a specific application, a depending service, or the infrastructure.
The post Lessons for Building and Monitoring Scalable ASP.NET Services! appeared first on Dynatrace blog – monitoring redefined.
gashland
- Managed SD-WAN Services - July 24, 2017
- LiveNX 6.2.0 - July 18, 2017
- User Authentication Monitoring - July 15, 2017

















