

This is part of Solutions Review’s Premium Content Series, a collection of contributed columns written by industry experts in maturing software categories. In this submission, Kasten by Veeam Gaurav Rishi highlights the four key layers of cloud-native data management and layers of operation.
 As containerized applications go through an accelerated pace of adoption, Day 2 services have become a here and now problem. These Day 2 services include data management functions such as backup and disaster recovery along with application mobility. In this new world of containerized cloud-native applications, microservices use multiple data services (MongoDB, Redis, Kafka, etc.) and storage technologies to store state and are typically deployed in multiple locations (regions, clouds, on-premises).
As containerized applications go through an accelerated pace of adoption, Day 2 services have become a here and now problem. These Day 2 services include data management functions such as backup and disaster recovery along with application mobility. In this new world of containerized cloud-native applications, microservices use multiple data services (MongoDB, Redis, Kafka, etc.) and storage technologies to store state and are typically deployed in multiple locations (regions, clouds, on-premises).
In this environment, where legacy infrastructure or hypervisor-based solutions don’t work, what are the right constructs for designing and implementing these data management functions for cloud-native applications? How should you reason about the various data management options provided by storage vendors, data services vendors, and cloud vendors to decide the right approach for your environment and needs? This piece dives under the covers and addresses the pros and cons of various data management approaches across several attributes including consistency, storage requirements, and performance.
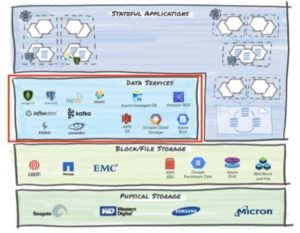
Defining a Vocabulary To start, we’ll deconstruct and simplify a stack to show where the data may reside in a cloud-native application.

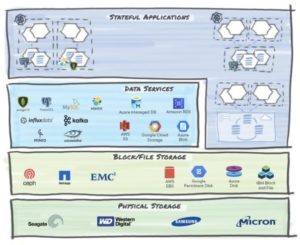
When thinking of data management, we could be operating on one (or more!) of the layers shown in the figure above. Let’s enumerate these layers:
1. Physical Storage
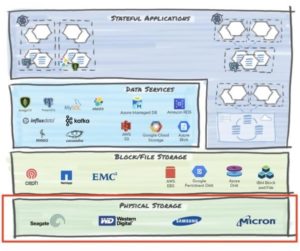
This layer includes various storage hardware options that can store state in non-volatile memory with a choice of physical media ranging from NVMe and SSD devices to spinning disks and even tape. They come in different form factors including arrays and stand-alone rack servers.
Physical storage could be located:
- On-premises, where you may encounter storage hardware from vendors such as Seagate, Western Digital, and Micron.
- In a managed cloud provider’s data centers. While you may never encounter a physical device, you know it’s there giving that “cloud” gravity!
2. File and Block Storage
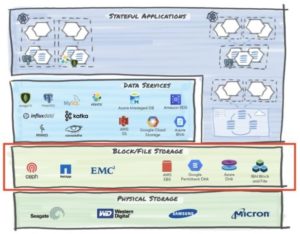
This software layer provides File or Block level constructs to enable efficient read and write operations from the underlying physical storage. In both cases (file and block), the underlying storage could be stand-alone (local disks) or a shared networked resource (NAS or SAN).
- Block storage implementations allow you to create raw storage volumes from local or remote disks that have low latency and are accessible through protocols such as iSCSI and FiberChannel. Block storage implementations on cloud providers include Amazon EBS and GCE Persistent Disks.
- File Storage provides shared storage for file semantics and operations using protocols such as NFS and SMB. File storage implementations commonly found on-premises include products from NetApp and Dell EMC. File storage implementations on cloud providers include Amazon EFS, Google Cloud Filestore, and Azure Files.
This layer often provides snapshotting capabilities to make a point-in-time copy of your volume for protection. Also, in Kubernetes environments, this layer provides Container Storage Interface (CSI) drivers to normalize the APIs that higher layers can exercise to call out snapshotting functions. Note that not all implementations of CSI are created equal in terms of the supported capabilities.
3. Data Services
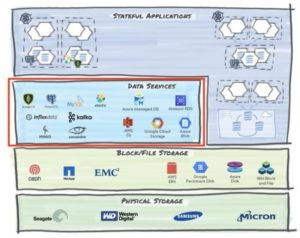
This layer resides on top of the file/block storage implementation. It provides various database implementations as well as an increasingly popular storage type, namely object (aka blob) storage. This is the layer that applications typically interface with and the choice of the underlying database implementations is based on the workloads and business logic. With microservices-based applications, polyglot persistence is the norm since every microservice picks the most appropriate data service for the job at hand.
Some of the database types and a subset of example implementations include:
- SQL Databases: MySQL, PostgreSQL, SQL Server
- NoSQL Databases:
- Key-Value Stores: Redis, BerkeleyDB
- Time-series Databases: InfluxDB, Prometheus
- Graph Databases: Neo4j, GraphDB
- Wide-column stores: Cassandra, Azure Cosmos
- Document stores: MongoDB, CouchDB
- Message Queues: Kafka, RabbitMQ, Amazon SQS
- Object Stores1: Amazon S3, Google Cloud Storage, Minio
There are also several hosted implementations of these databases, commonly referred to as Database-as-a-Service (DBaaS) systems. These typically include one of the database categories listed above and can sometimes provide auto-scaling along with the consumption economics of an as-a-Service (-aaS) business. Examples of DBaaS systems include Amazon RDS, MongoDB Atlas, and Azure SQL.
From the perspective of data protection, each one of the database implementations provides a specific set of utilities (pg_dump or WAL-E for PostgreSQL, mongodump for MongoDB, etc.) to backup and restore data. It is important to note that there are many utilities available with widely varying capabilities in terms of consistency, recovery granularity, and speed. They are usually restricted to a particular database implementation or, at best, a database type regardless of whether they are provided as a standalone utility or as a part of an -aaS offering.
4. Stateful Application
The application layer is where the business logic resides and, in the cloud-native world, applications are typically based on modern agile development methodologies and implemented as distributed microservices. Almost all applications have state that needs to persist. While there are several patterns of storing application state, we need to persist and protect the following information in the context of a stateful Kubernetes application as an atomic unit:
- Application Data: Across various Data Services, Block, and File storage implementations spread across multiple containers.
- Application Definition and Configuration: Application image and the associated environment configuration spread across various Kubernetes objects including ConfigMaps, Secrets, etc.
- Other Configuration State: Including CI/CD pipeline state, release information and associated Helm deployment metadata.
It is important to note that, for real-world deployments, the application is composed of hundreds of these underlying components. Also, in a cloud-native construct, the unit of atomicity for protection needs to be the application vs. the underlying data service or storage infrastructure layer. As enumerated earlier, this is because an application’s state includes the application data, definition, and configuration that is spread across multiple physical or virtual nodes and data services.
Final Thoughts
From a backup/recovery and application portability perspective, a good data management solution needs to treat the entire application as the unit of atomicity, rendering traditional hypervisor-centric solutions obsolete. We also illustrated a simple stack diagram to show where the application state actually resides from the perspective of various data services, block, and file stores as well as physical storage across both on-premises and cloud implementations. This defines a basic vocabulary that allows us to dive under the covers of the layers of operations of cloud data management.

Gaurav Rishi
Gaurav Rishi is the VP of Product at Kasten by Veeam. He is at the forefront of several Kubernetes ecosystem partnerships and has been a frequent speaker and author on cloud-native innovations. He previously led Strategy and Product Management for Cisco's Cloud Media Processing business.
















