

This is part of Solutions Review’s Premium Content Series, a collection of contributed columns written by industry experts in maturing software categories. In this submission, Kyligence co-founder and CTO Yang Li asks the question: “Is data modeling dead?” The answer may surprise you.
 An article on Substack entitled The Death of Data Modeling has aroused heated discussions among data practitioners. According to the article, many of those data practitioners feel that the classic data modeling process is no longer suitable for today’s data analysis needs. The author suggests that this is because data modeling has been overtaken by “the proliferation of Agile, the shift to engineering-lead organizations, and implementation friction.” But reports of the death of data modeling are premature. It has not died but, like most useful things in tech, it has evolved.
An article on Substack entitled The Death of Data Modeling has aroused heated discussions among data practitioners. According to the article, many of those data practitioners feel that the classic data modeling process is no longer suitable for today’s data analysis needs. The author suggests that this is because data modeling has been overtaken by “the proliferation of Agile, the shift to engineering-lead organizations, and implementation friction.” But reports of the death of data modeling are premature. It has not died but, like most useful things in tech, it has evolved.
In response, this article elaborates on why people think data modeling is dead and looks at the pain points and challenges enterprises face with the old approach to data modeling. The concept of Data Modeling 2.0 is introduced, and then we then explain how this new generation of data modeling can help enterprises overcome the challenges associated with traditional data modeling to achieve more governed and outstanding self-service data analysis.

Data Silos and Misaligned Data/Metric Definitions
At its core, data modeling is the organization of an enterprise’s data and the creation of models that make it easy for its users to consume in a meaningful and consistent way. However, the chaos attending the use of data models has affected the delivery of expected results as the metrics employed by business users are often ambiguous and unaligned.
This chaos has caused many CIOs to grow anxious about the effects of traditional data models as their organizations and data stores scale. For example, if a company uses a medium-sized business intelligence (BI) or data warehouse, it will soon be flooded with aggregation tables since different ETL tasks and aggregation tables will be created by each engineering-lead team. Correspondingly, hundreds or thousands of tables will need to be created; and if each report has more than ten metrics, there will be tens or even hundreds of thousands of business metrics with no assurance of consistent definitions, or that the data is even being used.
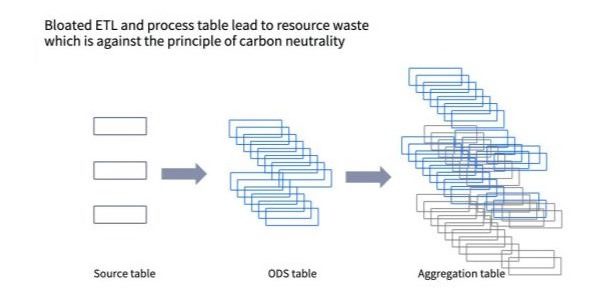
Source: Kyligence
Long Time-to-Insight with Costly Data Engineering Efforts
For analysts, the traditional data model delivery process has a long time-to-insight (TTI) cycle, and can only be used to analyze the already developed, known data, rather than gain insight into an unknown area, which is of little business help. For engineers, it means a lot of repetitive development work, high development overhead, and a low sense of achievement.

Source: Kyligence
The traditional delivery mode centered on data models usually requires a series of development processes: requirement analysis, data sourcing, ETL pipeline implementation, dashboard creation, and user acceptance testing (UAT). For example, this data delivery process typically takes 12 business days for a real company. That is unacceptable by today’s on-demand standards.
Besides, as data engineers usually need to serve more than one team, they lack sufficient understanding of the business behind the data models, nor do they have enough manpower to keep up with changing business needs. This leads to a long development and delivery cycle, which also means the business team needs to get involved deeply to make sure data requirements go live properly.
Business Users Don’t Know Where to Find Trusted Data
Business users are also in an awkward position. When they need the data, they do not know where to find trusted data–or even if there is trusted data available–which greatly impacts their productivity. As more data tables are produced by different data teams, a large number of tasks and aggregation tables in these tables are not properly governed, and data consumers (business users) soon don’t know which data should be used to answer their questions. The data warehouse that should provide everyone with value has become a “data swamp” that only a few senior data engineers can access and explore.
For example, the management team in a company with an IT infrastructure built on multiple cloud platforms will periodically review cloud costs, check whether the billing of various projects exceeds the budget, and then formulate the next cloud spending budget plan. However, if during an audit the management team can only find doubts from previous reports rather than the root cause behind them, they will end up spending more time debating the meaning of a “cost” and the accuracy of its formula, rather than improving the cost-effectiveness; and if comments on the revision of the report are made, but no governance are applied, the underlying problems will remain for the next audit, and the next audit, and the next. The cycle goes on and on.
Ideal Data Modeling
Faced with these challenges, we sketched out what data modeling should look like, as we believe data modeling should be the cornerstone of a data-driven business and bring about the democratization of business analytics.
- Data models should be managed in a central place, enriched with unified and consistent definitions, and serve as a common data language such that, when we talk about a key metric “cost,” it always means the same thing.
- Data engineers should build models such that data is translated into business language and with consistent governance, ensuring the data is trusted and of value to business users.
- A data engineering team should deliver business requirements more agilely without going through a lengthy requirement communication process.
- Business users should be able to access and use data autonomously, without over-reliance on data engineers, thus ensuring data democratization.
Is Data Modeling Really Dead?
The answer to the question “is data modeling really dead?” is an emphatic NO. The enterprise data platform remains closely related to good data modeling. What is “dead” (or should be) is data modeling without proper governance, and so what is needed is a new approach to data modeling: Data Modeling 2.0, which balances centralized data governance with agile, self-service analytics.
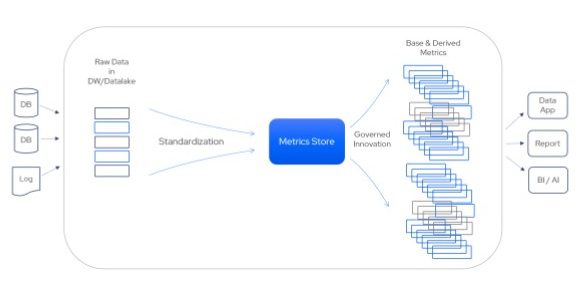
Source: Kyligence
By rethinking the data modeling around the metrics concept, we found the metrics store to be an exemplar of Data Modeling 2.0, as shown in the figure above.
Metrics Store: For Technical and Business Needs
A metrics store serves as a single source of truth for the enterprise. It is a centralized and governed repository for organizations to define, store, and serve key metrics. And we can divide these into base and derived metrics. To the left of the metrics store, base metrics are constructed from raw data, typically by a data engineering team, through a governed process to define a common data language in the form of metrics. To the right of the metrics store, business teams use BI or other data tools to consume and create derived metrics on top of the base metrics to fulfill data innovations in a self-service manner.
With a metrics store, data engineering teams can now focus on a set of standard base metrics, saving them from endless and often redundant data development projects, ensuring the consistency of data policy within the organization and achieving better data governance. It not only combines metrics with enriched business semantics but also with more consolidated and optimized data preparation pipelines to save operational costs.
By speaking the metrics language, business teams can now create and derive their scenario-based business metrics based on base metrics without needing support from the data engineering team. For example, if a supply chain manager wants to quantify the potential cost-saving by introducing a new materials supplier in a certain country or region, he or she can easily create the required metrics by deriving them from base supplier cost metrics, applying the proper business formula, and obtaining results independent of engineering team support. A business case can then be made by comparing the base supplier cost and the derived one. The same approach can be applied across the entire organization, making business innovation possible for everyone.
And by placing the data store between an enterprise’s tech and business operations, it is positioned ideally to also collect metadata and provide an AI-augmented analytics experience. For example, by studying the collection of metrics query metadata, the AI engine can:
- Recommend popular metrics to interested constituencies to promote data collaboration;
- Identify cold metrics and automatically move related data assets to cheaper storage to save IT cost; or,
- Suggest new metrics by detecting the common query pattern from a large group of different users.
By intelligently leveraging metadata, a metrics store empowers business users with more augmented analysis capabilities and can help to unlock the value behind data, generating operational and cost efficiencies for data engineers and business users. A metrics store strikes a good balance between governance and innovation, enabling citizen analysts to use data more efficiently while freeing engineers from the direct support of each user and project.
Under Data Modeling 2.0, data engineers can now focus on creating a standard set of base metrics and no longer be overwhelmed by data requests from all over the company. Meanwhile, business users are empowered by the metrics data language to navigate and explore the data world, verifying business innovation ideas using metrics tools all by themselves.
Remember that long, costly 12 business day time-to-insight cycle discussed at the outset of this article? One top bank in China that struggled with protracted analytics delivery built a metrics store under the Data Modeling 2.0 approach and quickly achieved significant savings in data operations efforts. As shown below, the bank identified 50 metrics development requirements for the data engineering team, 30 of which already existed in their metrics store and were thus able to be reused; ten more metrics were able to be derived from existing metrics, meaning 40 of the initial required metrics were quickly available to the business team on a self-serve basis.
Because of those efficiencies, the data engineering team was able to focus on the ten remaining new requests instead of the original 50. And, after the second round of request clarifications, it was discovered that five of those requests could be resolved by deriving them from existing ones, leaving only five new base metrics to be implemented instead of 50. And on top of those efficiencies, the total turnaround time was reduced from 12 business days to just five–a full week faster.
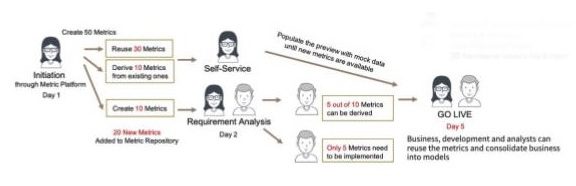
Source: Kyligence
Summary
While some may believe data modeling is dead, they would be mistaken. It merely needs a new paradigm, one that balances data governance and data innovation. Within this new paradigm–Data Modeling 2.0–a metrics store serves as a centralized source of truth that translates technical data language into business data language. And by speaking the same metrics data language, data collaboration, and data-driven business innovation are made simple and efficient for everyone.

Yang Li
Yang Li is co-founder and CTO of Kyligence, Apache Kylin co-creator, and PMC member. Yang is tech lead and architect of Kylin, focusing on big data analysis, parallel computation, data index, relational algebra, approximation algorithm, and other technologies. Previously, Yang was senior architect of eBay’s Analytic Data Infrastructure department and tech lead of IBM InfoSphere BigInsights, responsible for the Hadoop open source platform and winner of the Outstanding Technical Achievement Award.

















