

Federate, Query, and Optimize: Assembling Diverse Inputs for AI Innovation
Data teams struggle to feed artificial intelligence (AI) models the diverse, often far-flung inputs that they need. On the one hand, they cannot simply consolidate everything, given the complexity of migration. On the other hand, federated querying of data in place can drive up compute costs. These dual challenges deprive AI initiatives of critical inputs.
Compute-optimized queries can ease such challenges. With this approach, data teams assign query jobs to different compute engines based on their processing requirements. By streamlining workloads in this fashion, compute-optimized queries can reduce costs and thereby improve the return on investment (ROI) of AI initiatives. This blog assesses the opportunity and use cases for this type of approach.
Distributed and complex
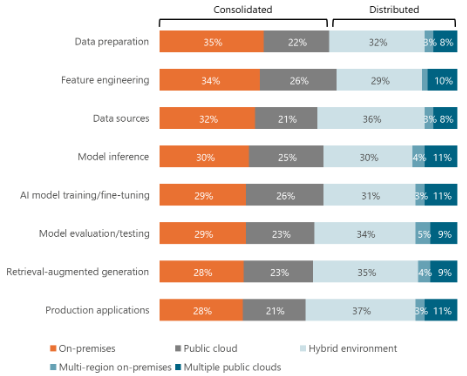
We start by assessing the state of data and AI environments. A BARC survey earlier this year showed that 47 percent of organizations host their AI data sources in more than one place; that is, in hybrid environments, multiple clouds, or multiple regions on-premises. Other aspects of AI projects, including feature engineering, model training/fine-tuning, and retrieval-augmented generation (RAG), are similarly distributed. These numbers illustrate that many AI projects straddle more than one data platform. This creates the need for some type of federated querying capability.
Where does your organization host the following components of its AI projects? (n=318)
Federated queries
Data and AI stakeholders query distributed data at many points in an AI project. A data engineer and data scientist might explore Workday records in the cloud, an Oracle database on-premises, and Internet of Things (IoT) sensor logs at the edge, all to define features for machine learning (ML). The data scientist might further refine features as she trains and evaluates ML models. She may also retrieve subsets of this data, along with technical documentation, to feed a RAG workflow for generative AI (GenAI). Federated queries enable these stakeholders to access distinct datasets as needed.
Data engineers and scientists query distributed data at many points in an AI project.
Traditional methods
Now let’s consider what’s happening under the covers. Building on our prior example, the data engineer executes Structured Query Language (SQL) commands to search, find, and retrieve data from each platform. Then he merges them into a single file on Databricks, ready for the data scientist to transform for feature engineering on Dataiku. Apache Spark engines handle the computation for all these operations. The problem is that the engine, in this case Apache Spark, might consume a lot of costly Amazon Web Services (AWS) compute cycles along the way, exceeding budgets and hurting the project’s profitability. Bulk-processing methods like this can also slow performance.
Enter the compute-optimized query
The alternative is to take a more surgical approach. Compute-optimized queries orchestrate the query workload and compute engine to make the best use of precious compute cycles while minimizing the need for data movement. In this scenario, the data engineer and data scientist might use Zetaris to query Workday with Google Compute Engine, Oracle with a local Hewlett Packard Enterprise (HPE) server, and IoT sensor logs with DuckDB. And they might merge the outputs in memory to give AI models the real-time views they need for training, inference, and RAG.
Compute-optimized queries streamline the processing, enabling organizations to support a wider array of AI use cases while meeting budget and performance requirements. For example:
- Retailers can run ML-based demand-forecasting models by querying distributed point-of-sale data, supply-chain systems, and e-commerce clickstreams with the most efficient compute engine for each source.
- Healthcare providers can accelerate clinical decision support by running compute-optimized queries across electronic health records and medical-device telemetry in branch offices, as well as cloud-based imaging repositories.
- Telecommunications providers can use ML anomaly detection to analyze and tune network performance based on real-time views of distributed telemetry logs and the centralized service fleet system.
- Finance teams can use GenAI and ML to streamline procurement processes by auto-generating contracts, recommending user actions, and identifying fraud risks. The data inputs might span regional enterprise resource planning (ERP) systems, a centralized merchant database, and external credit rating agencies.
- Information technology (IT) teams can resolve issues faster by using natural language processing (NLP) and GenAI chatbots that query product documentation, service ticket histories, and external security advisory systems.
Compute-optimized queries offer a practical way to overcome the cost and complexity of accessing distributed data for AI. By matching each workload to the most efficient compute engine, data and AI teams can reclaim budgets, accelerate pipelines, and broaden the range of viable AI use cases. Data and AI leaders should assess where their projects currently rely on federated queries and pilot compute-optimized approaches that deliver faster, more cost-effective, and scalable AI innovation.
This article was sponsored by Zetaris. Data and AI leaders should check out Zetaris to better understand their options in this space.





