

Rise of the Meta Catalog: Integrating Metadata for AI Innovation
Note: This blog was sponsored by Pentaho.
The data catalog is like a restaurant menu: it organizes food for AI. But the meta catalog is like DoorDash because it aggregates menus to expand choice and reach.
AI adopters now embrace this concept. They combine catalogs into meta catalogs that organize wide-ranging metadata across the enterprise, expanding options and enriching inputs for AI projects. This blog explores new primary research about this trend and assesses the implications for AI innovation.
Let’s start with definitions.
Metadata is information that describes data, models, agents, users, and other elements of an organization’s data estate. Data engineers, analysts, and scientists use catalogs to index, search, govern, query, and share metadata. A business analyst might use a catalog to find the latest regional sales data, request read-only access, and send it to colleagues. A data scientist, meanwhile, might use a catalog to identify features for an ML model or curate documents for a GenAI retrieval-augmented generation (RAG) workflow.
A catalog is an inventory of metadata that describes data, models, agents, users and other elements in support of AI projects.
The meta catalog goes further to organize and share metadata among multiple catalogs and tools. A rising cadre of catalog vendors offer meta catalog capabilities.
Survey Methodology
To assess the state of cataloging, BARC polled 165 data stakeholders at organizations that have 1,000 to 20,000 employees. Most (69%) of them reside in North America and the rest in Europe. We focused on regulated industries — banking, insurance, financial services, energy, utilities, healthcare, life sciences, telecommunications, and the public sector — because we believe regulations force these enterprises to govern their data more responsibly. Data teams in other industries can therefore learn from their practices.
Not Your Father’s Data Catalog
Data teams in regulated industries go well beyond traditional tables. They also use catalogs to organize metadata for new data types and AI/ML artifacts. More than a third (40%) of survey respondents catalog images, video, and sound files, and 32% catalog documents. In addition, 38% of them catalog AI/ML models and 31% catalog agents.
Which of the following elements do you address with your catalog/metadata management tool(s)? (n=163)
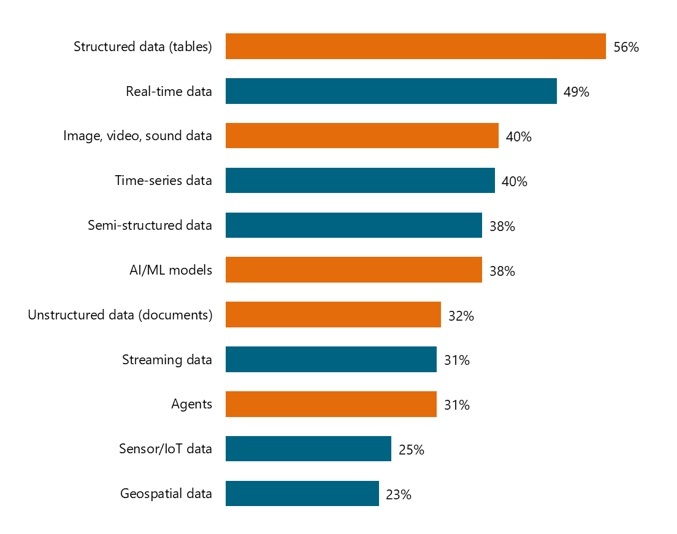
Many organizations now catalog metadata for new data types, AI/ML models, and agents
These trends, while promising, still lag overall AI adoption. A separate BARC survey shows that 50% of AI adopters are already in production with agents. Put these numbers together, and we see that many organizations deploy agents without cataloging them. AI and governance teams must close this gap to meet requirements for transparency, explainability, and auditability. Still, AI adopters and catalog vendors have come a long way considering that agents only become a mainstream concept in late 2024. They’re working quickly to integrate agents into their governance frameworks.
Many organizations put agents into production without cataloging them.
Rise of the Meta Catalog
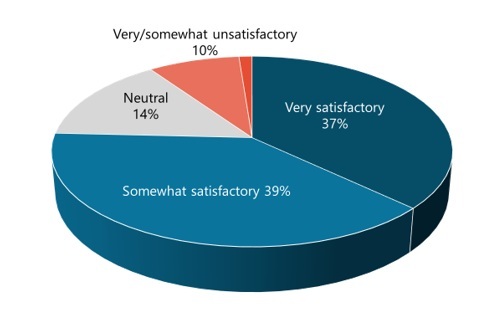
Regulated enterprises show surprising success with meta catalogs: in fact, 37% of our survey respondents are very satisfied with their ability to integrate metadata across the enterprise.
How would you rate your ability to integrate, organize, and view metadata across catalogs/metadata management tools? (n=165)
This successful usage of meta catalogs bodes well for AI projects. A meta catalog enables AI teams to train, prompt, and operate advanced models with accurate, governed inputs from a wider range of sources than would otherwise be possible with a traditional catalog. For example:
- A hospital chain might use a meta catalog to support a GenAI research agent that helps doctors diagnose patient conditions.
- A financial services firm might use a meta catalog to support a GenAI agent that analyzes thousands of transcripts to help private wealth managers calm panicky investors during a market downturn.
In cases like these, meta catalogs enrich the inputs and therefore the outputs of agentic AI.
Familiar Challenges
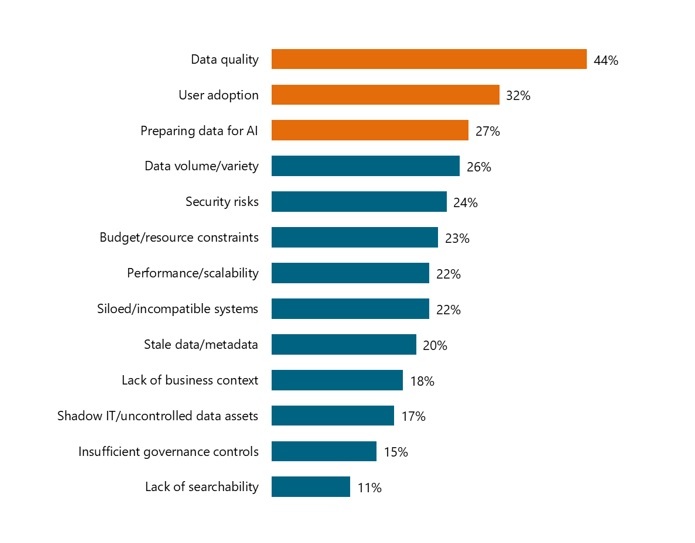
Like all AI adopters, regulated organizations face familiar challenges. Data quality, user adoption, and data preparation top the list.
- Data Quality: Duplicative, incomplete, inconsistent, stale, or invalid data continues to plague most organizations. It undermines the success of catalogs, analytics, and AI.
- User Adoption: Many managers and analysts avoid catalogs due to habit or restrictive software licenses. They get their data via shortcuts and workarounds, undermining data quality and raising governance risks.
- Data Preparation: Data engineers, analysts, and scientists struggle to prepare high volumes of diverse data for AI. It takes a lot of effort to merge, filter, format, and otherwise transform data into consistent inputs for effective cataloging.
These obstacles can make AI outputs untrustworthy, derail projects, and hurt return on investment (ROI). The meta catalog helps data teams overcome these obstacles by standardizing data quality controls, user licensing, and data pipelines across the enterprise.
What are the top three challenges your organization faces with cataloging and metadata integration? (n=165)
Getting Started
For other data leaders, the message is clear: investing in comprehensive cataloging and meta catalog capabilities is no longer optional if AI initiatives are to scale responsibly. Those who strengthen metadata integration and adoption today will position themselves to deliver trusted, high-impact AI outcomes tomorrow.




