
Attunity Unveils Compose 3.0 for ETL at Warp Speed
-
 By
Tim King
, Executive Editor at Solutions Review
By
Tim King
, Executive Editor at Solutions Review - Data Integration News,
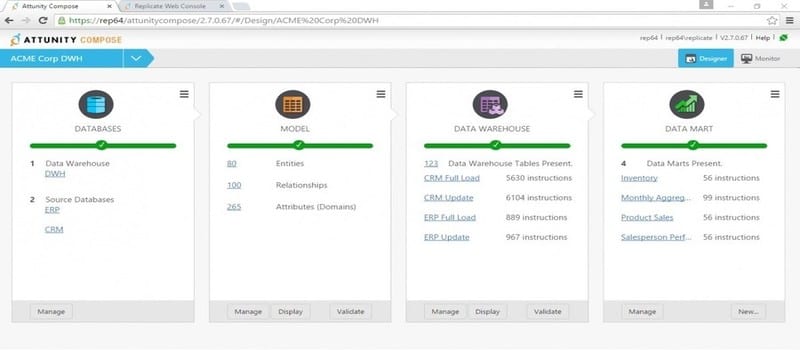
Attunity has announced the release of Attunity Compose 3.0, the latest major version of the vendor’s agile data warehouse automation solution. Version 3.0 offers enhancements for enterprise use cases including 10 times faster extract, transform, load (ETL) processing speeds, as well as advanced DevOps capabilities that streamline the data warehouse design, development and deployment processes.
Attunity Compose 3.0 automates the design, implementation and updates of data warehouses and data marts while minimizing the manual design processes of data modeling, ETL generation and workflows, allowing organizations to speed up analytics projects, optimize development and ETL, and reduce risk.
Compose 3.0 includes the following feature enhancements:
- ETL performance: Significant optimizations leverage the power of the underlying data warehouse platform to provide faster processing
- Advanced Version Control: Integration with enterprise source control systems enables developers to easily roll back to earlier versions of the project while minimizing disruption
- Improved collaboration: Enables multi-user development projects by supporting concurrent development of models, mappings, and data marts
Attunity’s Chief Marketing Officer Itamar Ankorion speaks to the new release: “Enterprises today need a faster way to enable analytics, and deliver more value with quicker iterations and less resources. Compose 3.0 provides an innovative data warehouse automation solution to accommodate these needs with enhanced enterprise-class capabilities. As we see customers scale their deployments in scope and volume, we enhanced Attunity Compose to enable higher ETL performance and larger implementations.”
The announcement was made at TDWI Conference in Las Vegas, Nevada, and Attunity is showcasing the new offering at the event.
Widget not in any sidebars
Tim King
Executive Editor
Tim is Solutions Review's Executive Editor covering the human impact of AI on the future of work and learning. He is also the Media Strategist behind Insight Jam (1M+ on YouTube) events and programming. A 2017 and 2018 Most Influential Business Journalist and 2021 "Who's Who" in multiple categories, Tim is a recognized thought leader in enterprise tech and AI.
- The 17 Best AI Agents for Data Integration to Consider in 2026 - December 22, 2025
- The 27 Best AI Agents for Data Engineering to Consider in 2026 - December 11, 2025
- The 4 Best Informatica Online Training and Certifications for 2026 - December 1, 2025

















