
Pentaho Takes Big Data Lead with Apache Spark Integration
-
 By
Tim King
, Executive Editor at Solutions Review
By
Tim King
, Executive Editor at Solutions Review - Data Integration News,
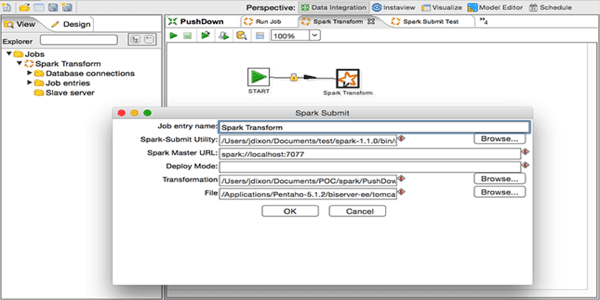
Pentaho yesterday announced support for native integration of Pentaho Data Integration with Apache Spark, which allows for the creation of Spark jobs. Initiated and developed by Pentaho Labs, this integration will enable the user to increase productivity, reduce costs, and lower the skill sets required as Spark becomes incorporated into new big data projects.
Spark is a powerful open-source processing engine built for speed, ease of use, and machine learning. It was engineered for performance, and is a next-generation big data technology used to store, blend, and govern data at new levels of speed, scalability, and simplicity. Pentaho was able to innovate early on with this emerging technology because it was built upon contemporary open source foundations.
Big data technologies are evolving at an almost immeasurable speed, and the folks at the Pentaho Labs continue to leverage and drive innovation in integration and analytics to give users advanced big data deployments with little risk. The company adds “Integration with Spark follows other labs efforts that have led to support for YARN and the Adaptive Big Data Layer. Following the native support of YARN alone, enterprise customers like RichRelevance, edo Interactive, and MultiPlan have been able to innovate and drive greater value from Hadoop.”
James Dixon, Chief Technology Officer at Pentaho notes: “For two years, we experimented with possible use cases based on our big data blueprints and sizing the enterprise market opportunity for Spark. Our customers now benefit from that work with simplified, real-time analytic capabilities. Our open-source heritage and modern extensible platform, allows us to quickly evolve our capabilities keeping our customers big data technology options open, reducing risk and saving considerable development time while taking advantage of the latest innovations in popular big data stores.”
Pentaho Data Integration for Apache Spark is available now in Pentaho Labs, and will be generally available in June of this year. To attend the webinar, click here, and for the official press release, click here.
Widget not in any sidebars
Tim King
Executive Editor
Tim is Solutions Review's Executive Editor covering the human impact of AI on the future of work and learning. He is also the Media Strategist behind Insight Jam (1M+ on YouTube) events and programming. A 2017 and 2018 Most Influential Business Journalist and 2021 "Who's Who" in multiple categories, Tim is a recognized thought leader in enterprise tech and AI.
- The 17 Best AI Agents for Data Integration to Consider in 2026 - December 22, 2025
- The 27 Best AI Agents for Data Engineering to Consider in 2026 - December 11, 2025
- The 4 Best Informatica Online Training and Certifications for 2026 - December 1, 2025

















