
Pentaho Unveils Data Integration Enhancements to Future-Proof Big Data
-
 By
Tim King
, Executive Editor at Solutions Review
By
Tim King
, Executive Editor at Solutions Review - Data Integration News,
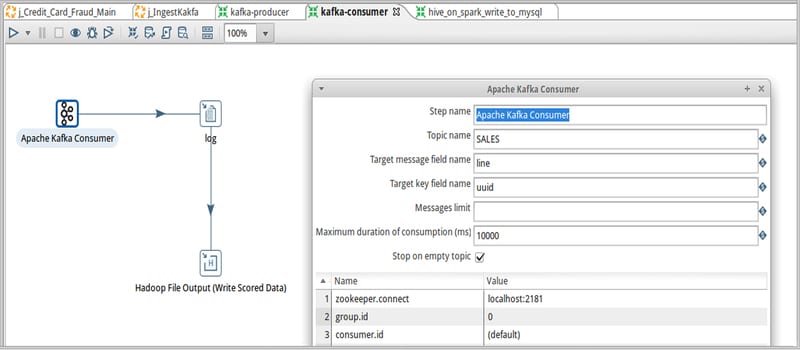
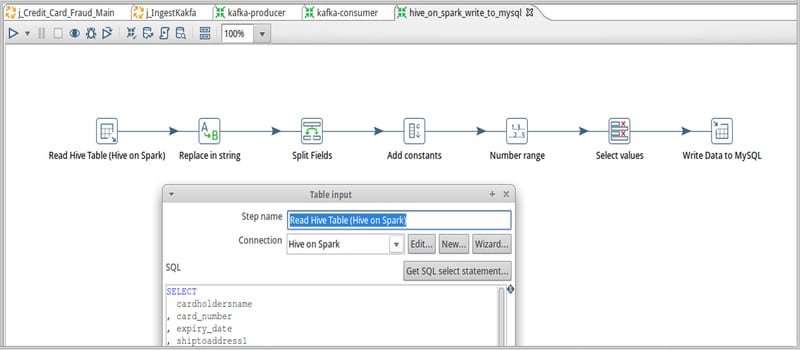
This morning, Pentaho unveiled five new improvements to help help enterprises overcome Big Data complexity, the skills gap and integration challenges in sophisticated environments. The announcement was made at the opening day of the 2016 Strata + Hadoop World conference. Perhaps the most notable feature enhancement present in this product update is an adaptation of SQL on Spark. The improvements help IT teams deliver value from Big Data projects faster, all while allowing organizations to utilize existing resources by eliminating the need for manual coding. This also provides for tighter security and more widespread support for Big Data technology ecosystems.
Pentaho Big Data Integration feature enhancements include:
- Expanded Spark integration: Lowers the skill barrier for Spark, flexibly coordinate, schedule, reuse, and manage Spark SQL in data pipelines, and integrate Spark apps into larger data processes to get more out of them.
- Expanded metadata injection tools: Allows data engineers to generate PDI transformations at runtime instead of having to hand-code each data source, reducing costs.
- Expanded Hadoop data security: Promotes better Big Data Governance, protecting clusters from intruders, including enhanced Kerberos integration for secure multi-user authentication and Apache Sentry integration for rule enforcement.
- Apache Kafka support: Provides enterprise customer support to send and receive data from Kafka, allowing users to facilitate continuous data processing use cases in Pentaho Data Integration.
- Increased support for additional Hadoop file formats: Supports the output of files in Avro and Parquet formats in Pentaho Data Integration, both popular for storing data in Hadoop in Big Data onboarding use cases.
Donna Prlich, Senior Vice President of Product Marketing at Pentaho, concludes: “Our latest enhancements reflect Pentaho’s continued mission to quickly make big data projects operational and deliver value by strengthening and supporting analytic data pipelines. Enterprises can focus on their big data deployments, removing the complexity and time involved in data preparation by taking advantage of new, high potential technologies like Spark and Kafka in the big data ecosystem.”
Read the official press release.
Widget not in any sidebars
Tim King
Executive Editor
Tim is Solutions Review's Executive Editor covering the human impact of AI on the future of work and learning. He is also the Media Strategist behind Insight Jam (1M+ on YouTube) events and programming. A 2017 and 2018 Most Influential Business Journalist and 2021 "Who's Who" in multiple categories, Tim is a recognized thought leader in enterprise tech and AI.
- The 17 Best AI Agents for Data Integration to Consider in 2026 - December 22, 2025
- The 27 Best AI Agents for Data Engineering to Consider in 2026 - December 11, 2025
- The 4 Best Informatica Online Training and Certifications for 2026 - December 1, 2025

















