
Tamr Secures US Patent for Enterprise-Scale Data Unification
-
 By
Tim King
, Executive Editor at Solutions Review
By
Tim King
, Executive Editor at Solutions Review - Data Integration News,
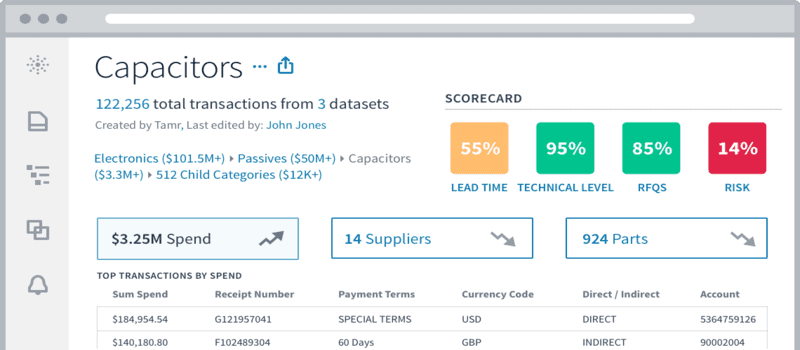
Tamr has announced that it has been issued a patent from the United States Patent and Trademark Office covering the principles underlying its enterprise-scale data unification platform. The patent, titled Method and System for Large Scale Data Curation, describes a comprehensive approach for integrating a large number of data sources by normalizing, cleaning, integrating, and deduplicating them using machine learning techniques supplemented by human expertise.
Tamr’s patent describes several features and advantages implemented in the company’s software, including: the techniques used to obtain training data for the machine learning algorithms; a unified methodology for linking attributes and database records in a holistic fashion; multiple methods for pruning the large space of candidate matches for scalability and high data volume considerations; and novel ways to generate highly relevant questions for experts across all stages of the data curation lifecycle.
Additional characteristics included in the platform covered by the patent include scalability through automation, data cleaning, non-programmer orientation, and incremental Data Integration and data curation.
Tamr’s co-founder and CTO Mike Stonebraker speaks to the announcement: “Our goal was to build an end-to-end system for enterprise-scale data curation that leveraged modern machine learning techniques to radically reduce the time and cost of producing clean, unified data sets. Tamr’s growth has proven the commercial value of the many innovations in our software, and this patent now confirms the uniqueness of our invention.”
Widget not in any sidebars
Tim King
Executive Editor
Tim is Solutions Review's Executive Editor covering the human impact of AI on the future of work and learning. He is also the Media Strategist behind Insight Jam (1M+ on YouTube) events and programming. A 2017 and 2018 Most Influential Business Journalist and 2021 "Who's Who" in multiple categories, Tim is a recognized thought leader in enterprise tech and AI.
- The 17 Best AI Agents for Data Integration to Consider in 2026 - December 22, 2025
- The 27 Best AI Agents for Data Engineering to Consider in 2026 - December 11, 2025
- The 4 Best Informatica Online Training and Certifications for 2026 - December 1, 2025

















