

Pilot to Production: A Modern Playbook for Agentic Analytics
Will agents help enterprises achieve the long-awaited goal of democratizing analytics? They might. In fact, the fast-emerging capability of agentic analytics empowers analysts, product leaders, and AI developers to make better decisions and build smarter workflows. This requires a modern architecture in which agents can securely access distributed data, reason about its meaning, and take safe actions.
- The semantic layer creates and queries data products across diverse sources.
- The metadata layer organizes information about data structures, usage, and relevance.
- The analytics agent converses with humans, generates insights, and orchestrates workflows.
- Governance controls enforce policies and monitor compliance across all these elements.
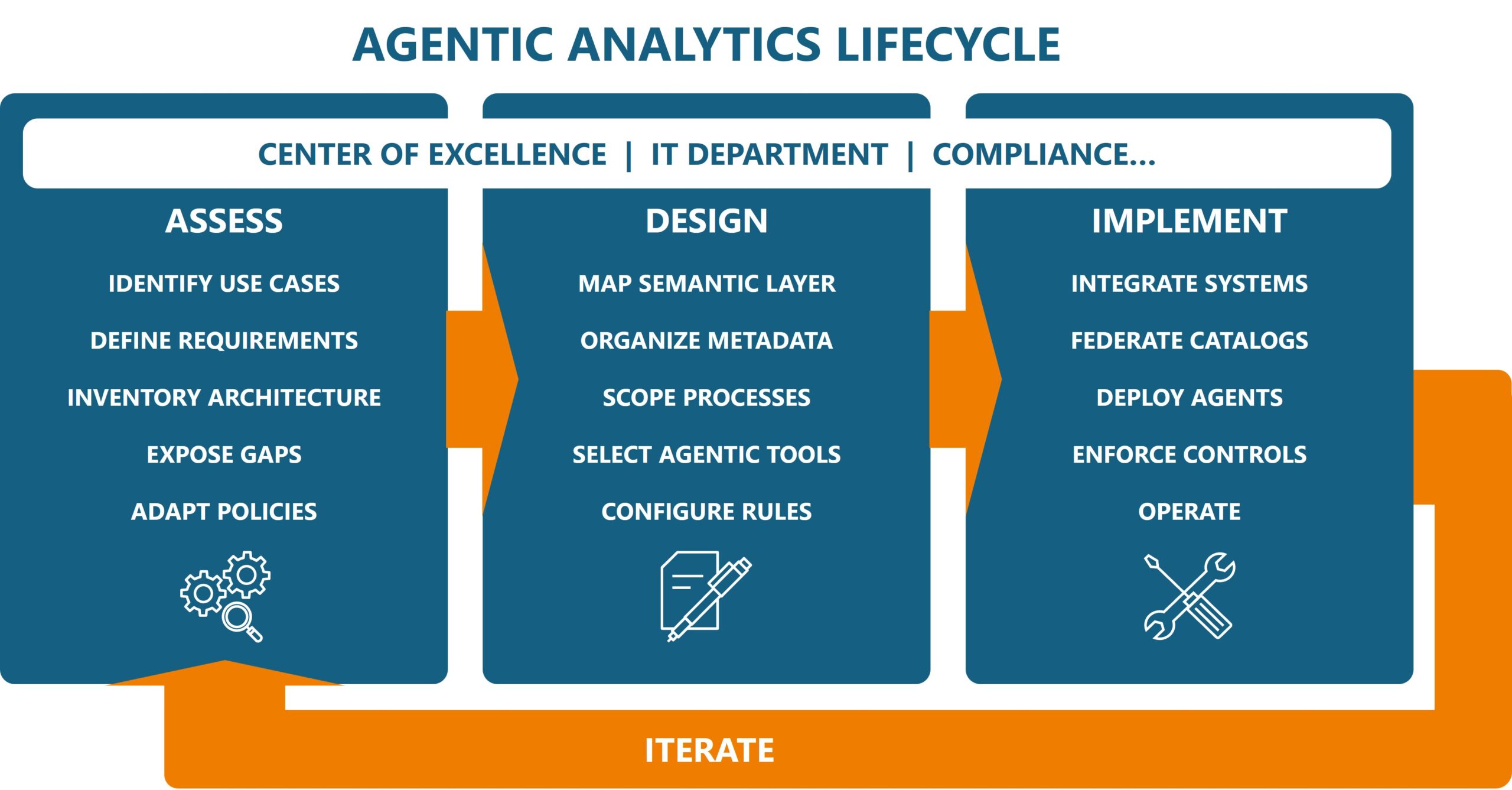
This blog proposes an agentic analytics lifecycle that helps enterprises build such an architecture and move projects into production with confidence. Our lifecycle has three phases: assessment, design, and implementation, with iterative loops back to assessment. We focus on champions such as the Center of Excellence (CoE), information technology (IT) department, and compliance team, who typically set AI strategy and/or provide budget under the direction of a C-level executive.
Here is how agentic analytics programs can succeed with each phase of the lifecycle. Spoiler alert: the more capabilities you get from commercial rather than homegrown tools, the simpler the implementation and the lower the risk.
Phase 1. Assess
The lifecycle starts with a hard-nosed assessment of what to achieve and how to achieve it. Champions prioritize use cases, define requirements, inventory their architecture, expose gaps, and adapt governance policies.
- Identify use cases. The CoE must ask business leaders: what prevents your managers from making good decisions and taking effective action? This question surfaces pain points such as rigid dashboards, business intelligence (BI) team backlogs, and inaccessible or stale data. It also sheds light on potential use cases, which the CoE can then prioritize by risk level (aim low) and scope (start small).
- Define requirements. Next, we define business and technical requirements. If the use case is reducing customer churn, the requirements might include achieving certain retention metrics and integrating accurate inputs across the data warehouse, website, and customer relationship management (CRM) system. They also might include agentic alerts and interventions, for example, to notify sales reps of high-risk accounts.
- Inventory architecture. Data architects and engineers within IT should assemble an inventory of key architectural elements, from data platforms up to the semantic and analytics layers. This gives the CoE a reference point for design decisions and tool evaluations, with a special focus on bringing together the right source data.
- Expose gaps. Many existing architectures lack critical new technologies such as vector databases and pipeline tools for unstructured data. Data architects, engineers, and analysts collaborate with machine learning (ML) engineers and data scientists to expose these gaps and feed them into technical requirements. These stakeholders come from IT and business units but contribute to the CoE.
- Adapt policies. Heritage data governance programs were not built to handle the risks that AI models and agents pose. Compliance and IT teams must adapt their current policies and create new ones to ensure agentic analytics initiatives have explainable logic, responsible outputs, and safe behavior. These policies should include robust training that guides humans to validate outputs and operate within clear guardrails.
Stakeholders prioritize use cases, define requirements, inventory the architecture, exposes gaps, and adapt governance policies in the assessment phase
Phase 2. Design
Now comes the design stage. Stakeholders map the semantic layer, catalog metadata, scope new processes, select their agentic tools, and configure governance rules.
- Map semantic layer. Many organizations already use semantic capabilities within each BI tool, which leads to a fragmented and inflexible analytics environment. Modern analytics, especially agentic analytics, requires an open, independent and unified semantic layer. Data architects and engineers within IT must implement this layer so they can map any tool to any source. They also might need to add capabilities such as document retrieval and federated queries for diverse data types.
- Organize metadata. Data architects and engineers should ensure their catalogs capture the metadata associated with all source inputs for agentic analytics. This includes business metadata such as a glossary, technical metadata such as schemas, operational metadata such as usage metrics, and governance metadata such as access rights. Such information becomes critical context for agent reasoning.
- Scope processes. Data engineers, ML engineers, and data scientists next scope how two critical processes will fit into their architecture. First, retrieval-augmented generation (RAG) enriches user prompts with relevant enterprise data to increase generative AI (GenAI) accuracy. Second, context engineering correlates inputs and metadata across the enterprise to help agents consider all relevant decision factors.
- Select agentic tools. Commercial offerings such as Simba Intelligence from insightsoftware Data + Analytics simplify design and implementation by baking many of these new technologies into supported software products. Ideally these tools will include both agentic analytics and the semantic, metadata, and RAG/context capabilities they require underneath. All the stakeholders cited above should help evaluate and select agentic tools.
- Configure rules. The design stage also includes governance. Data engineers, data stewards, and ML engineers configure technical rules that enforce governance policies and have them in place before implementation begins. This might include user access controls, or lineage views that trace agent actions back to model outputs and source data.
Stakeholders map the semantic layer, catalog metadata, scope new processes, select their agentic tools, and configure governance rules in the design phase
Phase 3. Implement
In the implementation stage, our champions integrate systems, federate catalogs, deploy agents, enforce controls, and operate new workflows.
- Integrate systems. Data architects and engineers collaborate with various colleagues to integrate the old and new elements. That new vector database must interoperate with the new agentic features within the heritage analytics tool. The new agentic analytics tool should play well with the lakehouse or other data platforms along with SaaS applications, catalogs, and so on. Model Context Protocol (MCP), Agent to Agent (A2A), and the Apache Iceberg open table format help glue things together.
- Federate catalogs. Many catalogs now can import and export metadata between one another. Data engineers, stewards, and data scientists can create federated “catalogs of catalogs” that provide comprehensive views of agentic analytics inputs. This improves the accuracy of RAG and context engineering.
- Deploy agents. ML engineers and data scientists deploy analytics agents with appropriate system prompts, tool access, and memory settings. Data analysts should test the agents with realistic Q&A before going into production. These stakeholders begin with the narrow, lower risk use cases identified in the assessment phase. They can expand after establishing a track record of accurate, explainable outputs.
- Enforce controls. Compliance and IT teams activate the governance rules configured during the design stage, ensuring that access controls, lineage tracking, and output monitoring are operational before agents reach business users. Data stewards audit agent behavior against established policies, flagging anomalies and feeding findings back into the assessment phase. This closed-loop oversight assists regulatory compliance and increases organizational trust.
- Operate. Once agents are live the CoE shifts into a steady-state operating model that treats agentic analytics as a managed capability rather than a finished project. Data engineers, analysts, and business stakeholders monitor performance metrics, refine the semantic and metadata layers, and incorporate user feedback to improve agent reasoning over time. As confidence grows, champions revisit the assessment phase to identify higher complexity use cases.
The implementation stage includes systems integration, catalog federation, agent deployment, enforcement of controls, and operation of new workflows
Agentic analytics represents a genuine inflection point for data democratization. Realizing its potential requires a disciplined lifecycle that spans assessment, design, and implementation with governance woven throughout. Organizations that invest in the right foundations, including a robust semantic layer, well-organized metadata, and commercially supported agentic tools, will move from pilot to production faster and with far less risk. They can start small, iterate with confidence, and expand use cases as trust accumulates.
To learn more, check out this new BARC report, Connect, Reason, and Govern: Activating Distributed Data with Agentic AI.





